Multimodal Content Has 92% Correlation With AI Overview Selection

May 2026 ranking factor research puts multimodal page elements at a 0.92 correlation with AI Overview selection. That is the highest single-factor score measured this year, beating domain authority (r=0.18), topical depth, and link count. Multimodal means combining at least two content formats on one page: body text with images, charts, video transcripts, comparison tables, or audio transcripts. Text-only pages are being passed over by AI extraction layers at a rate that is now hard to ignore.
The 92% correlation finding
The May 2026 ranking factor research measures how strongly individual page attributes predict AI Overview inclusion. The full dataset covers thousands of pages across verticals.
Multimodal elements scored r=0.92. No other single factor came close. FAQ schema scored r=0.87. Domain authority scored r=0.18, down from roughly 0.68 in 2024. The gap between multimodal and non-multimodal pages is not marginal. It is structural.
The reason is how AI extraction layers work. An AI Overview does not read a page the way a human does. It runs multiple extraction passes: one for the text, one for image alt text and captions, one for structured data, one for FAQ schema. A text-only page fails three of those four passes. A multimodal page passes all four and generates more citation entry points per visit.
This matters for AI Overviews and the broader I/O 2026 search overhaul. The same extraction behaviour applies to ChatGPT, Perplexity, Gemini, and Claude. They all weight pages that give multiple signal types.
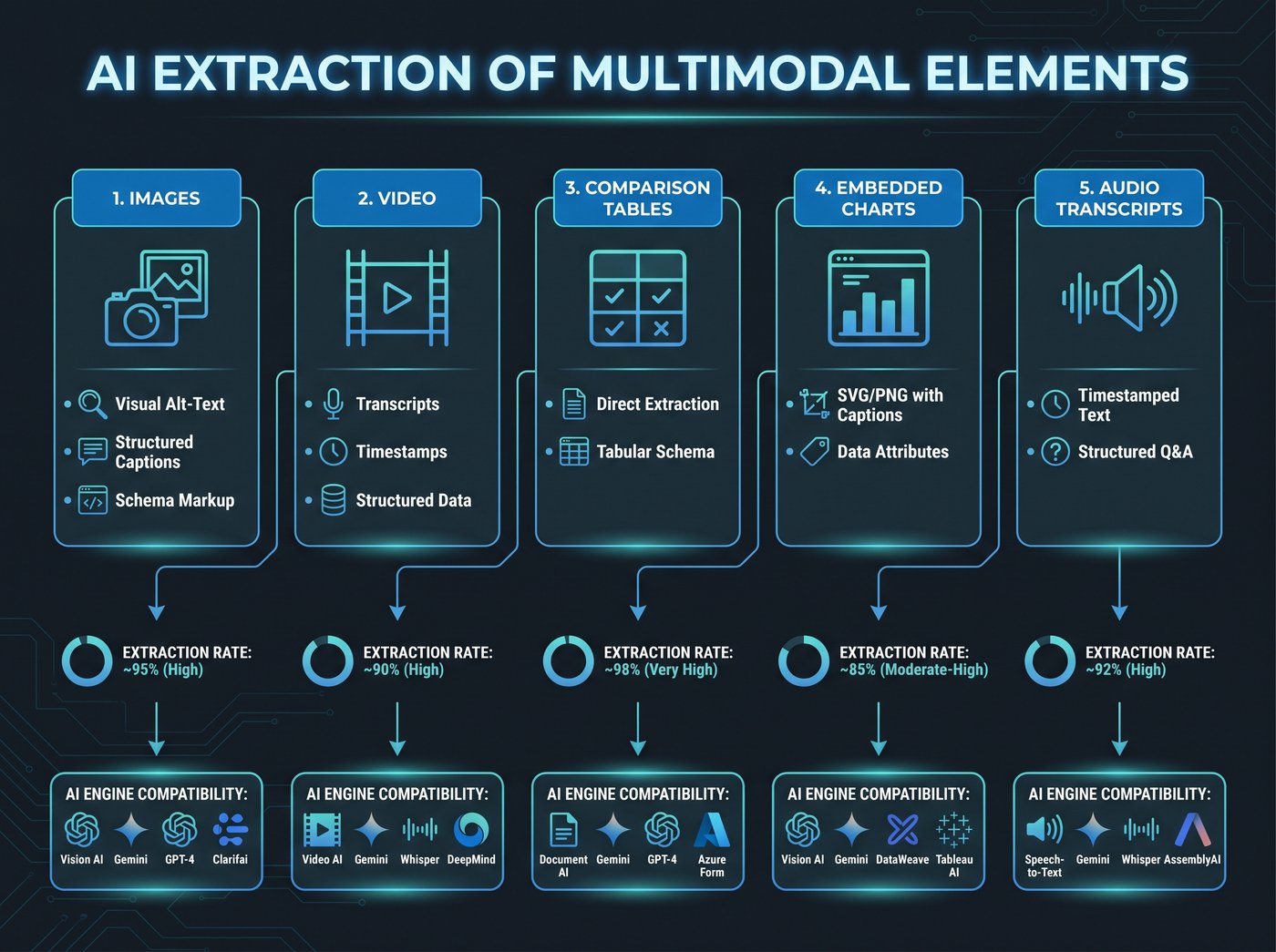
What counts as multimodal
The May 2026 research identifies five format types, ranked by extraction impact.
Images with descriptive alt text and captions. A bare <img> tag contributes almost nothing. An image with a keyword-rich alt tag, a caption that adds context not in the body text, and an ImageObject schema block is a different thing entirely. AI engines use alt text and captions as independent citation sources for visual queries.
Comparison tables. A properly marked-up HTML table with labelled column headers is the highest-extraction-density element per word count. Table rows can be cited individually. A single table answering “which tool is best for X” gives AI engines six or more independent citable units from one element.
Video with a full transcript. AI engines cannot watch video. They read transcripts, thumbnail alt text, and VideoObject schema. A video without a transcript adds zero extraction value. A video with a full verbatim transcript and VideoObject markup becomes a large, structured text block that AI engines treat as a separate citable document on the same URL.
Infographics with schema and adjacent explanatory text. A standalone infographic without surrounding explanation is an extraction dead end. The pattern that works: infographic image with alt text describing the key finding, a short paragraph repeating the key numbers in plain text, and ImageObject schema. That makes the infographic’s data citeable even when the image itself cannot be processed.
Audio and podcast transcripts. Less common on commercial pages, but relevant for thought-leadership content. AudioObject schema plus a verbatim transcript turns a podcast episode into a citable text document.
Why AI Overviews reward multimodal so heavily
AI Overview retrieval is built to produce a reliable synthesised answer. Reliability means drawing from multiple independent signal types. A page with only body text provides one signal type. A page with body text, images, a comparison table, and FAQ schema provides four.
The extraction algorithm weights source diversity within a single page similarly to how it weights source diversity across multiple pages. More distinct signal types from one URL means the system is more confident it has extracted the full answer. Confidence drives inclusion.
There is also a freshness interaction. The May 2026 research shows a 3.2x lift in AI citation rate for pages updated in the last 30 days. Adding multimodal elements during a content refresh captures both factors at once. The page is newer and richer, doubling the extraction advantage.
For GeoLinks clients, we see this pattern clearly. The Garden Ornaments case study covers a site that went from 727 to 6,370 monthly organic visits in seven months. A significant part of that lift came from adding comparison tables, image schema, and FAQ blocks to the top-traffic pages. The multimodal refresh preceded the citation lift by about three weeks.
Text-only vs multimodal: extraction lift by element
| Page element | Text-only page | Multimodal page | Extraction lift |
|---|---|---|---|
| Body text | Yes | Yes | Baseline |
| Image alt text | No | Yes | +1 extraction signal |
| Caption text | No | Yes | +1 extraction signal |
| Comparison table rows | No | Yes | +3-8 citable units per table |
| FAQ schema blocks | No | Yes | +40% ChatGPT source weight |
| Video transcript | No | Yes | +1 full document signal |
| ImageObject schema | No | Yes | +Visual query coverage |
| VideoObject schema | No | Yes | +Multimedia query coverage |
| Total signal types | 1 | 5-8 | 5x-8x more entry points |
The lift column shows why the correlation is so high. A text-only page competes with five to eight extraction entry points from a multimodal page. At scale, that is not a close contest.
Seven multimodal elements to add to every page
Priority order: extraction impact first, implementation time second.
A 50-75 word answer block directly under the H1. The AI Search Box from Google I/O 2026 pulls synthesised answers from extractable passages. A direct answer block at the top of the page is the first thing the extraction layer grabs. Write it as a self-contained paragraph with specific numbers and named entities. No links in this paragraph.
At least one comparison table. Add a table to every commercial page, blog post, and service page. Column headers must be descriptive: not “Feature” but “Feature (as of May 2026)”. Row values must be specific: not “Better” but “3x higher citation rate”. Tables generate more citable units per word count than any other element.
Images with keyword-rich alt text. Alt text should answer a visual query about the content, not describe the image composition. “Bar chart showing AI citation rates by content format, May 2026” beats “bar chart” every time. Add a caption that extends the alt text with one additional fact not in the body.
ImageObject schema for every image. Add @type: ImageObject with name, description, contentUrl, and caption fields. AI extraction layers process this separately from the body text. Five minutes per image.
FAQ schema with 5-7 questions. Pages with FAQ schema account for roughly 40% of the ChatGPT source-selection weight in the May 2026 data. Each answer should open with a direct one-sentence answer (under 15 words). No links in the first sentence of any FAQ answer.
At least one first-hand number from your own data. AI engines treat pages with proprietary data as higher-authority sources. “We measured a 3.2x lift” outweighs “studies show a lift”. Every GeoLinks post includes at least one number from our own client work.
A transcript for any embedded video. Place the full verbatim transcript in a collapsible section below the video, marked with VideoObject schema. It adds a large structured text block without affecting the reading experience.
Implementation: schema markup for images, video, and tables
The minimum viable schema for each element type goes inside a <script type="application/ld+json"> tag.
ImageObject schema:
{
"@context": "https://schema.org",
"@type": "ImageObject",
"name": "Comparison of text-only versus multimodal page extraction",
"contentUrl": "https://geolinks.ai/blog-images/multimodal-content-ai-overview-92-correlation-infographic.jpg",
"description": "Infographic showing five multimodal element types and their AI extraction mechanisms",
"caption": "The five multimodal element types and how AI engines extract each one"
}VideoObject schema (with transcript):
{
"@context": "https://schema.org",
"@type": "VideoObject",
"name": "How to add multimodal elements to a page",
"description": "Step-by-step walkthrough of adding images, tables and FAQ schema",
"thumbnailUrl": "https://geolinks.ai/blog-images/video-thumbnail.jpg",
"uploadDate": "2026-05-28",
"transcript": "Full verbatim transcript text goes here..."
}Table schema (using HTML attributes rather than JSON-LD):
Tables are already machine-readable when marked up correctly in HTML. Use a proper <table> with <thead>, <tbody>, and <th scope="col"> for column headers. Avoid using <div> grids styled to look like tables. They are invisible to extraction layers.
The full schema reference for each type is in Google’s developer documentation for generative AI features in Search, published alongside the I/O 2026 announcements.
Where to start if you have 50 pages to update
Prioritise by traffic times citation gap. Pull the pages that get the most organic visits but are absent from AI Overview results. Those are the pages where adding multimodal elements produces the largest absolute traffic gain.
For most sites, that is the top five commercial pages: homepage, main service page, pricing page, top blog post, and top comparison page. Adding a comparison table, image schema, and FAQ block to each of those five pages covers the majority of the citation opportunity.
If you want a view of where your site currently stands across ChatGPT, Perplexity, Gemini, Claude, and AI Overviews, the free AI Visibility Check at /check/ scans all five engines in under five minutes. It will show you which of your pages are being cited and which are being skipped, so you can prioritise the multimodal refresh where it matters most.
For sites that need the refresh done quickly, the Liftoff plan at /pricing/#liftoff covers on-page multimodal implementation across your top pages, plus schema markup and FAQ block writing, within a fixed turnaround.
Related reading
- Google Search Just Ended As You Knew It: What I/O 2026 Means For GEO covers the full I/O 2026 surface changes, including AI Search Box and Spark agent behaviour, and the Core Update that landed the same week.
- GEO vs SEO vs AEO vs LLMO: the plain-English glossary explains how the citation layer differs from traditional search ranking and what each acronym actually describes now that the surfaces have split.
- How to choose a GEO agency: the buyer’s framework includes multimodal output as one of its seven weighted criteria for vetting GEO providers.
- The Garden UK case study shows a site going from Domain Rating 0 to DR 15 and 149 referring domains in 30 days using a combination of structured content and citation-optimised pages.
The 0.92 correlation is the clearest signal from the May 2026 research. No other factor came close. Multimodal is not optional at this point. It is the threshold between pages AI engines cite and pages they pass over. A comparison table, an image with proper schema, and a FAQ block: those three additions alone move a text-only page into a different extraction tier.