ChatGPT's Monopoly Cracked: Claude Took 18.5% of AI Search

ChatGPT’s share of AI search referrals fell from 89.1% to 62.6% in under a year. Claude grew thirteen-fold to 18.5%, Gemini reached 10.6% and Perplexity 7.3%. Those are Goodie’s measured figures, published 21 May 2026. If your brand only optimises for ChatGPT, more than a third of AI search can no longer find you. This post sets out the multi-engine playbook the new numbers demand.
A 26.5-point fall in under a year
Goodie’s AI search traffic report compared two measurement waves. Wave one covered mid-2025. Wave two covered March and April 2026. Between them, the market stopped being a monopoly.
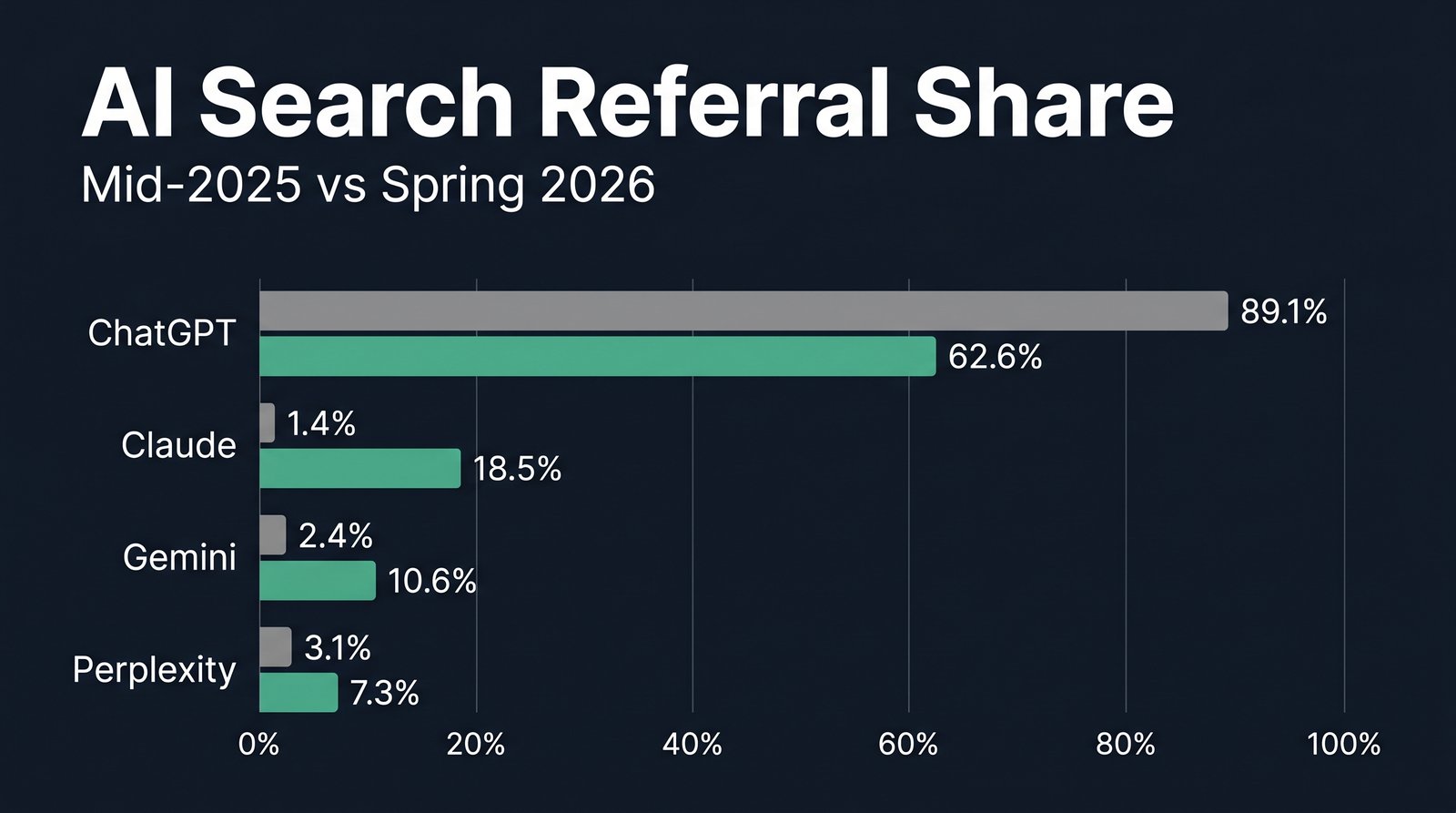
| Engine | Mid-2025 share | Mar-Apr 2026 share | Change |
|---|---|---|---|
| ChatGPT | 89.1% | 62.6% | -26.5 points |
| Claude | 1.4% | 18.5% | 13x |
| Gemini | 2.4% | 10.6% | 4.4x |
| Perplexity | 3.1% | 7.3% | 2.4x |
ChatGPT is still the biggest single source by a wide margin. Its referrals are still growing in absolute terms, as ChatGPT’s branded link update showed in May. But the engine that used to be nine-tenths of the channel is now under two-thirds of it. The other third belongs to engines most brands have never audited.
Why Claude grew thirteen-fold
Claude’s rise is the story inside the story. No other engine moved anything like as fast, and the causes are worth understanding because they are still running.
Anthropic turned Claude from a closed chatbot into a search product. Web search arrived for all users during 2025, and Claude now answers current questions with live citations. At the same time, Claude became the default brain inside a wave of agentic tools. Those agents browse, compare and recommend on a user’s behalf, and every recommendation sources from the open web.
The audience skews professional. Developers, analysts and operators live in Claude all day. Their commercial questions, which tools, which suppliers, which services, get asked where they already are.

A brand that is invisible to Claude is invisible to that entire audience. In mid-2025 that cost you 1.4% of the channel. It now costs you 18.5%.
Each engine reads the web differently
Treating AI search as one engine fails because each surface retrieves from a different place. Where the engine looks decides who it cites.

| Surface | Crawler | Retrieval leans on | What wins citations |
|---|---|---|---|
| ChatGPT | OAI-SearchBot, GPTBot | Bing-flavoured search, Wikipedia, Reddit | Entity clarity, third-party mentions |
| Claude | ClaudeBot | Brave search index | Crawlable pages, corroborated facts |
| Gemini | Googlebot | Google index, Knowledge Graph | Classic rankings, structured pages |
| AI Overviews | Googlebot | Google’s top results | Extractable answers, tables |
| Perplexity | PerplexityBot | Its own fast index | Fresh, specific, quotable pages |
The practical consequences are sharp. Block one crawler in your security settings and you vanish from that surface alone, often without noticing. Rank well on Google and you are most of the way to Gemini, since Google’s AI Mode overhaul builds on the existing index. Publish something genuinely fresh and Perplexity can pick it up first. We have measured Perplexity citations within 48 hours of a page going live.
The overlap is the playbook
Here is the good news. You do not need five strategies, because roughly 80% of the work is shared.
Every engine needs to crawl you. Your robots and firewall rules must admit OAI-SearchBot, ClaudeBot, PerplexityBot and Googlebot alike. Every engine resolves you as an entity, so your name, category and location must agree everywhere they appear. And every engine scores trust through corroboration: independent sites describing you without being asked.
That last signal is the heaviest. Around 91% of AI citations point at third-party sources rather than a brand’s own pages. The engines differ on retrieval, but they agree on trust.
The remaining 20% is engine-specific tuning. Reddit and review platforms weigh more in ChatGPT’s sourcing. Classic rankings carry Gemini. Freshness and quotable specifics carry Perplexity. The nine-point ChatGPT playbook covers the deepest surface; the other engines reuse most of its levers.
What our own campaigns show
We learned the multi-engine lesson on our own portfolio before the Goodie data made it official.
When we launched Garden UK from a fresh domain, the goal was to register as a real entity everywhere machines look, not just in one index. The site went from zero to Domain Rating 15 in 30 days. Referring domains grew from 27 to 149, a 452% rise, with every link brand-anchored and traffic-vetted.
That corroboration work paid on every surface at once. The same mentions that taught Google the brand existed taught Claude and Perplexity too, because all of them read the same open web. One campaign, five engines, no per-engine spend.
The reverse also holds. When we run visibility scans for prospects, the commonest pattern is a brand present in one engine and missing from the rest. The owner checked ChatGPT once, saw their name, and concluded the job was done. The other engines were never asked.
Cover all five surfaces this week
You can audit the gap in an afternoon. Ask ChatGPT, Claude, Gemini and Perplexity the same five buying questions your customers ask. Note which brands each engine names and where you appear. Then check your firewall and robots rules for every crawler in the table above, because a blocked bot explains an absence faster than any content theory.
If you would rather see it in one report, the free AI Visibility Check scans ChatGPT, Claude, Gemini, Perplexity and Google AI Overviews together and shows which queries cite you on each.
When the scan shows gaps, the fix is sustained, citable content plus the corroboration that every engine trusts. That is what the Content Engine package is built for: weekly answer-ready pages aimed at the questions all five surfaces are being asked, not just the one engine everyone watches.