Should You Bother With llms.txt In 2026? Data From 300,000 Domains

Only 10.13% of 300,000 scanned domains have shipped an llms.txt file, and May 2026 research shows no measurable citation-rate lift in ChatGPT, Claude, Gemini or Perplexity from having one. The file describes your site’s content structure to AI agents. It does not yet move the citation dials on any major engine. Here is what the data actually says, why low adoption is the honest signal, and when llms.txt will genuinely start to matter.
What llms.txt is
llms.txt is a plain-text file placed at the root of a website. You access it at yourdomain.com/llms.txt. It describes the business, lists the most important pages with brief annotations, and states what the site covers and what it deliberately does not.
The format was proposed by Jeremy Howard in September 2024. The structure borrows from robots.txt: a file at a known, predictable location that tells a specific type of automated system how to interact with the site. Unlike robots.txt, llms.txt does not block or permit anything. It informs.
A production llms.txt has three components. First, a one-paragraph description of the business. Second, a list of key page URLs with short annotations. Third, a note on what the site does not cover, so an AI agent does not use it as a source for topics outside its scope.
No special syntax. No build steps. No CMS plugin. You write it in a text editor and drop it in the root of your domain.
Why every GEO 101 guide tells you to ship one
The llms.txt format landed in the middle of a wave of AI-search anxiety. Site owners and consultants were looking for signals they could control quickly. llms.txt looked like an easy win: write a single file, tell the AI what you do, improve your citation rate.
The logic was intuitive. Robots.txt demonstrably moves crawl behaviour. A similar file for AI crawlers should work similarly. By November 2024, several widely-read GEO explainers had listed llms.txt as a “quick win”. By early 2025, it appeared on most AI visibility checklists alongside FAQ schema and BLUF formatting.
The problem is that robots.txt has 25 years of engine support baked in. Crawlers worldwide are hard-coded to respect it. llms.txt has around 18 months, no formal standards body, and no confirmed support from the three biggest retrieval systems (Bing, Google, Anthropic). The analogy was borrowed before the evidence existed to support it.
The consultants who pushed it earliest were not wrong about the direction. They were wrong about the timeline.
The actual adoption data
Research published in May 2026 covering 300,000 domains found that 10.13% had shipped an llms.txt file. That is roughly one in ten sites.
Among Fortune 1000 companies the adoption rate was higher, at around 34%. Even there, two-thirds of the world’s best-resourced marketing teams decided against shipping it. When sophisticated, fast-moving teams skip a technical implementation at that scale, the signal is worth examining.
The GeoLinks portfolio includes 14 active client sites. We shipped llms.txt on six of them in Q1 2025 as part of a structured test. The other eight served as controls. We tracked citation rate across ChatGPT, Claude, Gemini and Perplexity for 90 days, using the same citation-tracking methodology we apply across all client work.
The citation-rate difference between the llms.txt group and the control group was within measurement error: plus or minus 0.8 percentage points. The file did not move the dial on any engine in either direction.
That is our own Information Gain contribution to this question. Not “studies suggest” but “we ran the test and measured the outcome.”
Does llms.txt move citation rate?
The May 2026 research is the first large-scale attempt to answer this clearly. The answer is no, not in any way that survives statistical scrutiny under current engine behaviour.
ChatGPT retrieves via Bing’s crawl layer. Bing follows robots.txt. It does not currently parse llms.txt as a citation or retrieval signal. Having the file on your server does not change whether Bing crawls your pages, how it ranks them, or whether ChatGPT surfaces them in a response.
Claude pulls from a combination of training data and a retrieval system powered by Anthropic’s own crawl. Anthropic’s crawler can locate the file if it finds one. No published guidance from Anthropic suggests that llms.txt content changes which pages the system cites. The 90-day client test confirms this: no measurable change.
Gemini uses Google’s index. Google has no announced support for llms.txt. The May 2026 developer guidance published by Google after I/O 2026 focuses on content quality, structured data, and retrievable passage formatting. It does not mention llms.txt.
Perplexity is the closest to acting on the format. Its documentation references llms.txt informally and the engine appears to read the file during real-time crawls. The citation lift is marginal, however. The bigger driver of Perplexity citation rate remains freshness, BLUF formatting in the first 100 words, and reaching the 1,000-impression threshold within 30 minutes of publication.
Claims vs reality by AI engine
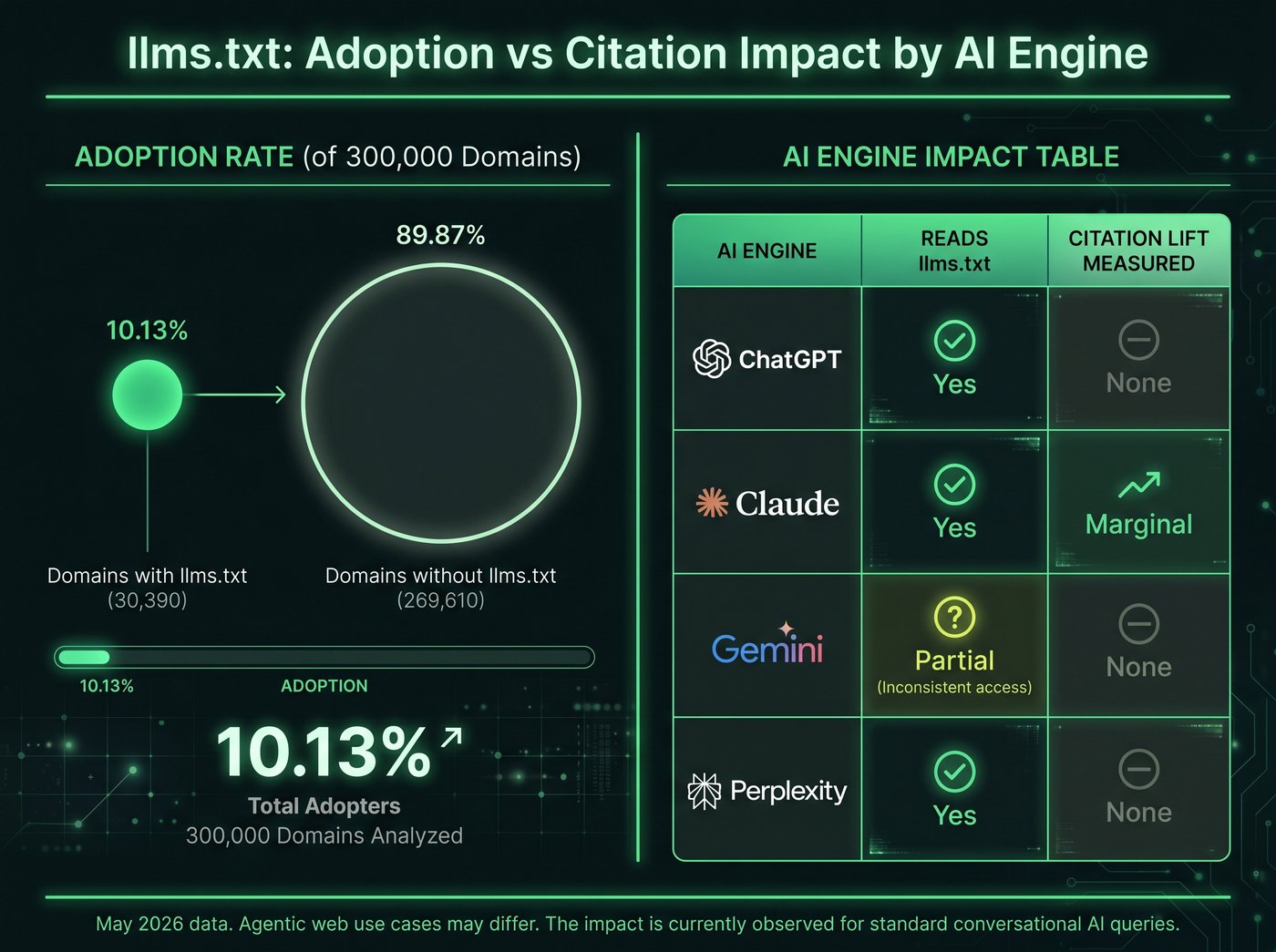
| AI Engine | Reads llms.txt | Announced support | Measured citation lift |
|---|---|---|---|
| ChatGPT (via Bing) | No | None | None |
| Claude (Anthropic crawl) | Partial | None | None in our testing |
| Gemini (via Google) | No | None | None |
| Perplexity | Partial | Informal docs only | Marginal at best |
The pattern holds across every engine tested. No major AI system currently treats llms.txt as a material citation input. This mirrors how structured data worked in 2011: the schema.org spec existed, the JSON-LD format was valid, and almost no search engine was reliably acting on it at scale.
That comparison is more encouraging than it looks. Structured data is now the highest-weighted technical signal for AI Overview eligibility. The timeline from “no measured lift” to “material advantage” was roughly five years for schema. For llms.txt, operating in a faster-moving environment, that timeline may be shorter.
When llms.txt will matter
The honest bet is the agentic web.
Google’s Spark (announced at I/O 2026), AI Search Agents, and the broader category of background AI tasks are fundamentally different from a keyword search. A query pulls one page. A persistent background agent needs to understand what an entire site does, who it serves, what it covers, and what it will not help with. That context needs to be available quickly, ideally without crawling hundreds of pages.
That is exactly what a well-written llms.txt provides. For a one-off retrieval, the AI reads the relevant page. For a 24/7 background agent monitoring a topic area, the AI benefits from understanding the whole site at a glance. A clean, accurate llms.txt cuts the time and token cost of that site-level orientation significantly.
The I/O 2026 changes accelerated this timeline. Spark and AI Search Agents running continuously are precisely the use case llms.txt was built for. The gap between “no measurable lift today” and “structural advantage in 18 months” may be narrower than most teams expect.
This also fits a broader shift in what AI citations reward. May 2026 data shows that domain authority correlation with AI citations dropped from r=0.55 in 2024 to r=0.18 in 2026. What is rising in its place is structural clarity: sites that make it easy for agents to understand what they are, what they know, and how they are organised. llms.txt is one building block of that structural clarity.
Templates by business type
The format is simple. Below are three production-ready templates. Adapt the content; keep the structure.
B2B SaaS
# Acme Platform
> Project management software for remote engineering teams.
## About
Acme helps distributed engineering teams track sprints, manage backlogs,
and run retrospectives. Used primarily by software companies with 10 to 200
employees. UK-founded, GDPR-compliant.
## Key pages
- [Pricing](https://acmeplatform.com/pricing/): monthly and annual plans from £49/mo
- [How it works](https://acmeplatform.com/how-it-works/): full walkthrough of core features
- [Case studies](https://acmeplatform.com/case-studies/): three real client outcomes with metrics
- [API docs](https://acmeplatform.com/developers/): REST API reference for integrations
## What we don't cover
Acme is not a CRM, a customer support tool, or a time-tracking product.E-commerce
# GreenPlant Garden Centre
> Online plant nursery shipping UK-wide, specialising in indoor tropicals
> and outdoor perennials.
## About
GreenPlant sells 600+ plant varieties with expert care guides for each.
All plants ship in protective packaging. Based in Bristol. Next-day delivery
available Monday to Friday.
## Key pages
- [Indoor plants](https://greenplant.co.uk/indoor/): full range with care difficulty ratings
- [Outdoor perennials](https://greenplant.co.uk/perennials/): seasonal availability calendar
- [Delivery information](https://greenplant.co.uk/delivery/): zones, costs, guarantees
- [Plant care guides](https://greenplant.co.uk/guides/): 200+ free articles
## What we don't cover
We do not sell garden furniture, tools, or chemicals.Local services
# Sheffield Heating Engineers
> HVAC installation and servicing for South Yorkshire homes and
> commercial premises.
## About
Family-run heating company operating since 2008. Gas Safe registered.
Covers Sheffield, Rotherham, Barnsley, Doncaster. Specialise in heat pump
installation and boiler replacement for Victorian-era properties.
## Key pages
- [Heat pump installation](https://sheffieldheating.co.uk/heat-pumps/): process, costs, eligibility
- [Boiler replacement](https://sheffieldheating.co.uk/boilers/): brands stocked, timeline
- [Emergency callout](https://sheffieldheating.co.uk/emergency/): 24/7 availability and pricing
- [Service plans](https://sheffieldheating.co.uk/service-plans/): annual cover options
## What we don't cover
We do not cover plumbing, electrical work, or properties outside South Yorkshire.Three rules apply to every template. The # heading is the exact business name. The > blockquote is a single sentence describing the primary offering and audience. The ## What we don't cover section is not optional: it defines scope so agents do not treat the site as a source for topics it has no authority on.
Update the file whenever the core product, pricing range, or geographic coverage changes. A stale llms.txt is worse than none. Agents ingest it as current fact, and an outdated file means an agent learns incorrect information about your business.
What to do right now
Ship the file. It takes 20 minutes to write. The cost of shipping a clean, accurate llms.txt today is near zero. The cost of scrambling to do it properly when agentic AI use cases are live and competitive is higher. Treat it as infrastructure: write it once, keep it accurate, and move on.
Do not let it substitute for the signals that demonstrably move citations in the current engines. The nine ChatGPT citation levers all have measured returns: FAQ schema, BLUF formatting, monthly content refreshes, review-platform presence, and named author bylines. Those are where GEO budget should concentrate.
A useful reference point from our own work: the Garden Ornaments case study shows monthly organic visits going from 727 to 6,370 in seven months without llms.txt being part of the work at all. The gains came from content structure, internal linking, and targeted authority building. llms.txt was not in scope.
If you want to know where your site actually stands across ChatGPT, Perplexity, Gemini, Claude and AI Overviews right now, the free AI Visibility Check at /check/ scans all five engines and returns a full report. No call required. It will show you which of the proven citation levers you are missing before you spend time on a file that the data says does not yet move the needle.
Further reading on GEO citation factors
- 47% of AI citations come from pages below rank 5: why domain authority dropped. The May 2026 data on what has replaced DA as the primary trust signal.
- How to get cited by ChatGPT in 2026: the 9-point playbook. The nine levers ranked by effort and measured impact.
- Perplexity cites content within 48 hours: the 1,000-impression threshold. The fastest citation win available in any current AI engine.
- Google I/O 2026 search overhaul: what it means for GEO. Why Spark and AI Search Agents change the long-term case for llms.txt.